Case Studies
AIM: Uzbrojeni w wiedzę przejrzymy sobie teraz autentyczne przykłady, jak nie powinniśmy sobie radzić z błędami w Node.js - każdy anty-przykład ma propozycję lepszego rozwiązania.
catch-all
process.on("uncaughtException", function(err) {
// ALL YOUR ERRORS ARE BELONG TO US
// YOU CANNOT STOP ME NOW!
});
process.on("uncaughtException", function(err) {
syslog.serializeError(err);
// ANOTHER ONE BITES THE DUST!
process.exit(1);
});
Oprócz tego, że łapanie wszystkich wyjątków w jednym miejscu jest z gruntu złe, taki mechanizm służy raczej jako zabezpieczenie, żeby aplikacja nie została zatrzymana.
W dokumentacji znajduje się wyjaśnienie dlaczego wykorzystanie tego zdarzenia jest antywzorcem, prowadzi do niestabilności i tak naprawdę pozostawia środowisko uruchomieniowe w stanie nieustalonym, nie gwarantując niczego.
To tak naprawdę ostateczny środek do zalogowania błędu, próby zapisania stanu aplikacji, być może wykonania operacji odwrotnych do wykonywanej logiki (tzw. rollback) i wyjścia.
GOOD: Powinniśmy mieć tu process.exit z odpowiednim kodem wyjścia (zgodny z Naszymi ustaleniami). Z własnego doświadczenia mogę powiedzieć, że np. można śmiało wykonać tzw. "last log" i wyjść - należy tylko pamiętać, że przy zapisie logów należy wykonać 'flush to disk', dla pewnych interfejsów wejścia / wyjścia może to być wymagane.
GOOD: Dodatkowo dobrą praktyką jest skonfigurowanie Node.js tak aby wykonywany był zrzut pamięci (core dump) przy każdym błędnym wyjściu, posiadanie takich informacji znacznie ułatwia analizę post-mortem - należy tylko pamiętać, że taki zrzut trochę waży i nie warto zapychać głównej partycji a np. tylko '/tmp'.
Dodatkowo ludzie związani z C++ i C, posiadający dostęp do podobnych mechanizmów (np. std::uncaught_exception itp.) uważają ich wykorzystanie za antipattern.
asynchronous-throw
http.get("http://ipinfo.io/8.8.8.8", function (response) {
response.pipe(concat(function (content) {
var object = JSON.parse(content);
console.log(object.loc);
}));
});
Tak jak wspominałem, błędy możemy dostarczać asynchronicznie lub synchronicznie, ale nigdy nie powinniśmy mieszać obu mechanizmów. Czy zakładając, że tego nie robimy jesteśmy bezpieczni?
Niekoniecznie, bo często nie robimy jednak tego świadomie - jak w zamieszczonym przypadku?
QUESTION: Co jest tutaj źle (brak obsługi zdarzenia 'error' ale ważniejszy jest JSON.parse który wyrzuci wyjątek dla nieprawidłowej składni JSON ale też i dla pustego łańcucha znaków lub 'undefined')?
Oczywiście mógłbym tutaj zaznaczyć dużo prostszy przypadek, z bezpośrednim 'throw' wewnątrz wywołania zwrotnego ale nie byłoby zabawy ;).
GOOD: Wystarczy złapać wyjątek w klauzulę try..catch i odpowiednio go obsłużyć np. porzez asynchroniczną propagację. Tutaj rodzi się też pytanie, że może warto pozwolić mu ubić konkretny proces bo jesteśmy na to przygotowani i ten worker akurat posiada supervisora. Mimo wszystko propagowałbym ten wyjątek wyżej i dopiero wtedy wyrzucił powodując ubicie procesu - ze względu na spójność mechanizmów obsługi błędów (czytelność i spójność rozwiązań w całym systemie).
error-handling-in-streams
response.pipe(saveToS3).pipe(temporarySaveToDisk);
// Better, but still bad:
response.pipe(saveToS3);
response.pipe(temporarySaveToDisk);
// Best (errorHandler is a PassThrough stream implementation):
response.pipe(errorHandler)
.pipe(saveToS3);
response.pipe(temporarySaveToDisk)
.on("error", function () { /*...*/ })
Na poprzednim slajdzie znajduje się jeszcze jeden błąd (o którym powiedzieliśmy lub nie) - nie obsługujemy zdarzenia 'error' dla strumienia (konkretnie jest konwencja wprowadzona przez prototyp EventEmitter dostępny w Node.js, z której strumień korzysta bo sam jest emiterem zdarzeń). Tam aby to poprawić wystarczy obsłużyć to zdarzenie i wykonać odpowiednią akcję.
Tutaj mamy trochę bardziej skomplikowany przypadek. Wyobraźmy sobie, że mamy endpoint który przyjmuje upload plików - omawiany plik chcemy zapisać w Amazon S3, ale od czasu do czasu Amazon jest niedostępny więc zapiszemy sobie go też na dysku na wszelki wypadek - jak S3 wróci, zuploadujemy wiszące pliki jeszcze raz.
Jeśli użyjemy chainingu, wszystko pięknie działa tylko jeśli operacja uploadu na S3 nie zwróci błędu. W innym przypadku łańcuch zostanie przerwany. Pomijam na razie fakt, że obsługi błędu w takim przypadku również nie ma, co spowoduje wyrzucenie wyjątku synchronicznie (brak handlera na 'error' === synchroniczne 'throw').
GOOD: Oprócz obsługi zdarzenia 'error', możemy wykorzystać do tego strumień PassThrough, który połknie błąd, przerwie łańcuch nie powodując dalszych błędów. Jednocześnie drugi strumień zapisze plik na dysk.
GOOD: Dwie dodaktowe uwagi: Co jeśli braknie miejsca na dysku? Obsługujemy to własnym error handlerem dla drugiego łańcucha strumieni. Druga uwaga: musimy zapewnić bezbłędną implementację strumienia PassThrough (obiekt 'errorHandler') tak aby błąd w nim nie powodował skutków ubocznych.
ignoring-errors
socket.on("connection", function (connection) { /*...*/ });
socket.on("disconnection", function () { /*...*/ });
socket.on("connection", function (connection) { /*...*/ });
socket.on("disconnection", function () { /*...*/ });
socket.on("error", function (err) { /*...*/ });
W tym przypadku brak handlera obsługi błędów skutktuje propagacją błędu wyżej.
Obsłgujmy błędy jak najbliżej miejsca ich wystąpienia (chyba, że świadomie propagujemy go wyżej do obsługi lub w celu zakończenia żywota określonego procesu).
GOOD: Zachowujmy konwencje stosowane w Node.js - praktycznie każda implementacja EventEmitter (na pewno wszystkie w bibliotece standardowej Node-a) wykorzystują zdarzenie 'error' w celu poinformowania konsumenta interfejsu, że zaszła nieoczekiwana sytuacja.
Jeśli macie przeczucie, że to prowadzi do zwiększenia ilości kodu związanego z obsługą błędów i zaciemnienia faktycznej logiki, macie racje. Jak scentralizować obsługę takich błędów, i odpowiednio wysuszyć sobie taki kod (DRY) opowiemy sobie za chwilę.
sound-of-silence
try {
unsafeOperationWhichEventuallyThrow(Math.rand());
} catch(e) {
// Oups!
}
try {
unsafeOperationWhichEventuallyThrow(Math.rand());
} catch(exception) {
syslog.reportError(level, exception);
business_logic.restore();
transaction.rollback();
}
To chyba najczęściej nadużywany mechanim "obsługi błędów" w przypadku programowania. Nie muszę cyba tłumaczyć dlaczego złapanie wyjątku i siedzenie cicho jest złe.
GOOD: Przynajmniej zalogujmy fakt obsługi wyjątku, jeśli jest bardzo źle i ten typ błędu jest nieodwracalny wywalmy aktualny proces i odtwórzmy stan aplikacji po restarcie. Jeśli błąd powstał po żądaniu pochodzącym od klienta - zaraportujmy odpowiedni kod błędu, zrestartujmy proces i pozwólmy klientowi wykonać żądanie ponownie, wraz z jego wersją obsługi tego typu sytuacji.
if-err-antipattern
fs.stat(path, function (err, stat) {
if (err) {
return done(err);
}
fs.open(path, "r+", function (err, fd) { /* DEEPER... */ });
});
var handler = require("domain").create();
handler.on("error", done);
fs.stat(path, handler.intercept(function (stat) {
fs.open(path, "r+", handler.intercept(function (fd) {
// ...
}));
}));
W przypadku zagnieżdżonej asynchronicznej logiki (bardzo często przy pracy z plikami, socketami) obsługa błędów przeradza się w koszmar 'if-err' powtarzany na każdym poziomie, w identyczny sposób. Oprócz duplikacji i złamania zasady DRY, zaciemnia kod i dokłada złożoność przypadkową do problemu
GOOD: wystarczy wykorzystać domeny i metodę '.intercept' która przechwtuje każde wywołanie zwrotne i błąd z niego, do wspólnego, zcentralizowanego error handlera. Jeśli błąd nie wystąpi, sterowanie zostanie przekazane wgłąb do wywołania zwrotnego.
Domeny (za pomocą metod '.add' lub '.run') automatycznie przechwytują timery, zdarzenia 'error' z EventEmitter (więc i błędy ze strumieni) i inne nisko poziomowe detale. Centralizują w ten sposób obsługę zasobów i mechanizm obsługi błędów.
Domeny posiadają swoje wady (np. nie zamykają połączeń TCP, nie zawsze zamkną deskryptory plików, nie potrafią przechwycić wyjątku wyrzuconego z warstwy natywnej) co więcej API i sposób użycia nie przekonał opiekunów Node.js i firmy związane z jego rozwojem oraz nie rozwiązał największej bolączki jaką jest obcięty stos wywołań, dlatego powstają nowe rozwiązania takie jak Zone (wzorowane na Zone.js dostępnym w AngularJS 2.0), które będą propozycją do dołączenia ich do rdzenia Node.js.
discard-my-resources
try {
setInterval(importantLogic, 1000);
itWillThrow();
} catch(e) {
syslog.error(e);
// OH YOU DIRTY, LITTLE BASTARD...
}
var timer;
try {
timer = setInterval(importantLogic, 1000);
itWillThrow();
} catch(e) {
syslog.error(e);
clearInterval(timer);
}
Zadziwiające jest jak bardzo nie dbamy o zewnętrznie zaalokowane zasoby w przypadku obsługi błędów (np. połączenia do bazy, timery, otwarte deskryptory plików). Cały czas pokutuje myślenie, że JS ma GC i to on za Nas posprząta.
O ile w przypadku "let it crash" przy wyjściu z procesu wszystkim zajmie się system operacyjny, o tyle w przypadku obsługi błędów musimy o sprzątanie zadbać sami.
GOOD: Zgodnie z dobrą praktyką "każdy 'new' posiada 'delete'" tak i reszta kodu związana z alokacją zewnętrznych zasobów powinna posiadać odpowiednik go zwalniający. Często zapomina się, że w JS mamy sekcję 'finally' jeśli chodzi o obsługę błędów.
exception-as-a-logic-flow
for (i = 0; i < N; ++i) {
for (j = i + 1; j < N; ++j) {
if (specialCondition()) {
throw "CONTINUE-WITH-FLOW";
}
}
}
for (i = 0; i < N; ++i) {
for (j = i + 1; j < N; ++j) {
if (specialCondition()) {
return true;
}
}
}
To właściwie kolejny klasyk, wbrew pozorom nie taki rzadki jeśli chodzi o występowanie. Sterowanie przepływem i logiką aplikacji za pomocą wyjątków jest po prostu złym wykorzystaniem tego mechanizmu. Nie jest ani mądre, ani czytelniejsze - jest po prostu błędne.
GOOD: Należy tak zaprojektować logikę, aby takie akrobacje rodem z cyrku nie były potrzebne.
Argument o zmniejszonej wydajności już nie jest aktualny. Owszem, w przeszłości V8 dokonywał deoptymalizacji konkretnej funkcji, jeśli zawierała ona try..catch, ale obecnie nie każdy try..catch negatywnie wpływa na wydajność i optymalizację określonych funkcji.
design-hijacked-by-a-library
asynchronousOperationFromLibrary(arg, function(result, err) {
// IT'S NOT AN ERROR, IT'S BROKEN CONVENTION
});
asynchronousOperationFromLibrary(arg, function(err, result) {
// NOW IT'S BETTER
});
Tak jak można nadużyć standardowego mechanizmu wbudowanego w język, tak samo spotyka się rozwiązania których design jest ewidentnie sterowany określoną biblioteką. W najprostszym przypadku mamy do czynienia tylko ze złamaniem konwencji - w gorszej sytuacji mamy masę kodu spaghetti, który wykorzystuje bibliotekę i to jej konwencje oraz design wdarły się do faktycznego kodu (vide nadużywanie async.js jako biblioteki do sterowania logiką i przepływem informacji).
GOOD: Należy tak zaprojektować logikę, aby takie akrobacje rodem z cyrku nie były potrzebne.
vapourous-details
try {
/*...*/
} catch(original_err) {
throw "My Error Happened!"
}
try {
/*...*/
} catch(original_err) {
throw new VError(original_err, 'Domain error: %s', argument);
}
Przechwytując wyjątek bardzo często wykonujemy pewną akcję i wyrzucamy swój wyjątek, specyficzny dla domeny lub naszych standardów.
GOOD: Po pierwsze zawsze rozszerzajmy standardowy prototyp 'Error' - nie budujmy własnych abstrakcji, korzystajmy z tego co jest. Nic nie stoi na przeszkodzie aby wykorzystywać istniejące pola (message, name, stack) ale również dokładać własne specyficzne. Szczególnie potrzebne jest pole 'name' za pomocą którego możemy rozpoznać typ wyjątku, czego nie zapewnia nam klauzula 'catch'. To co jest równie ważne, to opakowanie oryginalnego wyjątku w Nasz własny, tak aby oryginalne szczegóły nie wyparowały z mechanizmu obsługi błędów. Do tego celu służy świetny moduł 'verror'.
wrong-abstraction
using wrong abstraction in wrong place
var domain = require("domain");
domain.create().run(function () {
// WHY SO DOMAIN?
JSON.parse("")
});
To raczej problem z designem aplikacji i zrozumieniem jak działają poszczególne elementy. Zdarza się, że pewne sytuacje dot. sposobu komunikacji błędu pasują naturalnie w pewnym przypadku. Zdarza się także, sytuacja odwrotna - że nie mamy kompletnie pomysłu jak zaraportować dany błąd, albo nawet mamy problem z rozróżnieniem czy błąd jest typowo operacyjny czy może to błąd typowo programistyczny.
GOOD: Tutaj nie ma złotych rad. Tak jak w przypadku tworzenia API nowego modułu, tak i tutaj potrzeba doświadczenia, zrozumienia domeny i realizowanej funkcjonalności ale przede wszystkim wiedzy jak poszczególne "building blocks" działają i do czego służą. I dlaczego np. komunikowanie błędu za pomocą zdarzenia 'error' w EventEmitterze w jednym przypadku, będzie pożądane a w innym niekoniecznie.
meh-i-have-promises
readFilePromise("config.json")
.then(function (text) {
return JSON.parse(text);
}, function (err) {
// DAMN YOU JSON.parse, NOT AGAIN!
return defaultConfig;
});
readFilePromise("config.json")
.then(function (text) {
return JSON.parse(text);
})
.then(null, function (err) {
// Now it's okay.
return defaultConfig;
});
Promises to bardzo pomocne narzędzie, niemniej jednak nie zwalnia z myślenia. Dodatkowo praktycznie każda implementacja, nawet zgodna ze standardem Promises/A+ dokłada własną złożoność przypadkową oraz własne API i "smak".
GOOD: Wykorzystanie promises dalej może być niebezpieczne, jeśli dobrze nie poznamy mechanizmu z którego korzystamy. Kod może być ładniejszy i czytelniejszy, niemniej jednak dalej podatny na błędy i nie zabezpieczony odpowienio przed sytuacjami wyjątkowymi.
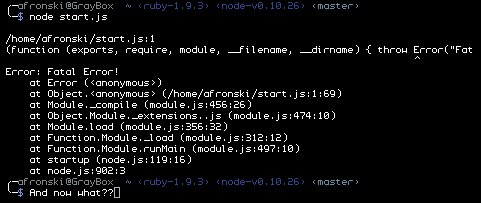
the-ultimate-stack-trace
Error: Fatal Error! Oh no, now what? :(
at Error (<anonymous>)
at node.js:902:3
# And logs collected in one place e.g. rsyslog:
2014-08-13T11:59:59.000Z APP2 as2.app.com
[FATAL] Syntax error in configuration: unexpected empty string.
2014-08-13T12:00:02.000Z APP1 as1.app.com
[WARN] Invalid attributes passed to important service: "null"
2014-08-13T12:00:02.000Z APP1 as1.app.com
[ERROR] Remote peer unavailable:
URL: app2.app.com:8080/get_important_data?q=null
Status code: 500
Body: Fatal Error! Oh no, now what? :(
Przyzwyczajeni z innych języków i środowisk, przykładamy bardzo dużą wagę do stosu wywołań. Tymczasem w Node.js i w każdym asynchronicznym środowisku, (bez specjalnego wsparcia) stack trace nie niesie zbyt wielu cennych informacji ze sobą ze względu na swoją asynchroniczną naturę.
GOOD: Potrzebujemy czegoś więcej - możemy wykorzystywać Zone i gorąco polecam do zapoznania się z tematem, ponieważ dzięki nim uzyskamy pełen, asynchroniczny stack trace. Są do dyspozycji inne moduły np. 'async-stacktrace' ale koniec końców poleganie tylko na stack trace jest krótkowzroczne i na dłuższą metę w dużej rozproszonej, wieloprocesowej aplikacji się nie sprawdzi.
GOOD: Zdecydowanie polecam się uzbroić w dobry mechanizm logów (np. 'bunyan' z zapisem do sysloga), druga sprawa to core dumpy generowane przy wyjściu z aplikacji. Kolejnym elementem jest zaawansowany system monitoringu oraz możliwość introspekcji na środowisku produkcyjnym za pomocą 'dtrace', która jest zdecydowanie cenniejsza od pełnego stack trace - ponieważ daje więcej informacji np. pełen stan, dostep do metryk systemu operacyjnego i łatwy dostęp do wewnętrznych liczników platformy Node.js. Minusem 'dtrace' jest wymaganie dot. deploymentu na SmartOS (Solaris) lub systemach *BSD ze względu na sposób licencjonowania tego narzędzia. Port Linuxowy jest coraz lepszy, nie jest jednak zalecany do zastosowań produkcyjnych.