Interesting Language Features - Erlang II
This blog post is an article from a series which contains examples, explanations and details about interesting features of various programming languages. I have collected several examples of different characteristics, which definitely extended my view regarding programming, architecture and structure in general. I would love to hear your feedback about presented choices or description of yours favorite programming language feature.
Introduction
In previous blog post, we talked about pattern matching and its usage in functional programming in general. But Erlang is more known in the programming community from something different. This programming language, with support for distribution and concurrency baked in since beginning, is mostly known as a solid foundation for reliable, long running systems, maintained for many years. It was developed this way deliberately with all mentioned features in mind, because of requirements imposed by telecommunications industry from the 80s. Moreover, these requirements are still actual for today’s IT systems. We can benefit from the whole platform, especially if we have to deal with strict requirements related with reliability and fault-tolerance.
Erlang’s unique features related with concurrency, reliability and distribution are based on very simple concepts - isolation, lightweight processes and powerful VM implementation. Back in a days, Erlang needs for distribution was argued because of hardware redundancy. If you want to have fault-tolerant system, you need at least two computers. You need to provide redundancy and simply put - two machines are able to handle multiple errors, one machine handles only the first error. ![]()
But, if you have multiple concurrent processes, you need to treat errors differently - classic way of error handling or defensive programming techniques will not help us here. Erlang’s famous motto for that situations is let it crash. It does not mean, that we should crash whole VM in case of error, We need to deal with them in a different way and with different tools - supervisors with their hierarchies and ability to connect and observe other processes. I would like to focus on the second group.
Links and Monitors
Isolation is a very wise choice when it comes to the reliability, because we can avoid cascading failures. But, how you will know that something actually failed? Besides isolation, the very important thing is to have ability to observe other processes. By connecting two processes together via link, you are creating the bidirectional bond - if one of them fails, both processes will be killed.
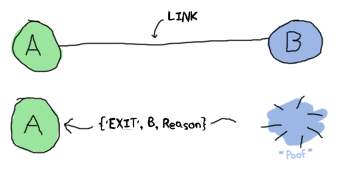 Image shamelessly taken from the amazing book Learn You Some Erlang For Great Good!
Image shamelessly taken from the amazing book Learn You Some Erlang For Great Good!
It sounds useful - you can group processes together with common concerns and bring them down together in case of error. Disabling a link is possible on both sides. But what if we would like to have more granular control on the exiting flow. We can either monitor a second process or trap exits. Lets look on the second method at first:
process_flag(trap_exit, true).By doing that, process which trap exits will receive an additional message to the mailbox if the linked processes will exit abruptly with an erroneous reason. Also, if the process itself will exit with an error - exit signal will be trapped. Only one type of error, called a kill invoked by the process itself, cannot be trapped - you can do it by exit(Pid, kill)..
Besides that you can observe other processes by setting unidirectional connection called a monitor. When the monitored process will go down, observer will receive a new message directly to the mailbox. As we said, it is a unidirectional relation, so it can be disabled only by the process that set up that connection earlier.
Origin
All of described ideas looks like a very high level concepts, but it is actually the opposite:
Links were invented by Mike Williams and based on the idea of a C-wire (a form of electrical circuit breaker).
Idea comes directly from the “C-wire” in early telephones. In order to cancel a problematic call, you should ground the C-wire. Electronics is always a very good place to collect a valuable inspiration regarding the system design and fault-tolerance. ![]()